
I've been mulling this topic for a while and didn't really know how I wanted to present it, but with Linus Torvalds' recent appearance in the news trashing GitHub's suggested commit feature, I figured I should probably capitalize on the subject matter and just start writing. The goal of this post is to stay tool-agnostic and even avoid the subject of code review and merge requests, but some mention will be unavoidable. This won't be about CI or CD or testing automation or build promotion or anything related to the process of getting your code into the place you want it to be.
I've worked on several projects in GitHub and a few in Gerrit and Bitbucket, and while I've never contributed to an email-based git project, I've watched a few long enough that I feel like I could avoid making a fool of myself. Across all the projects I've watched and worked on, across all the tools and opinionated review structures, there's been one constant: the average git commit is bad.
When your commits aren't a complete unit of work, they cost you units of work in searching costs later.
I'm thankful that my first professional experience developing software was with a project hosted with Gerrit because Gerrit imposes a unique restriction on the developer workflow that is reasonably contentious: a pull request is exactly one commit.
Most developers are familiar with GitHub's pull request system, as it's the most popular free repository host out there right now, and most major git projects are hosted or mirrored on the site. GitHub has no restrictions on the number of commits that can be included in a single pull request, and it leads to many "Fix X" types of commits and merges with tens of commits included. How many times have you seen a commit like this:
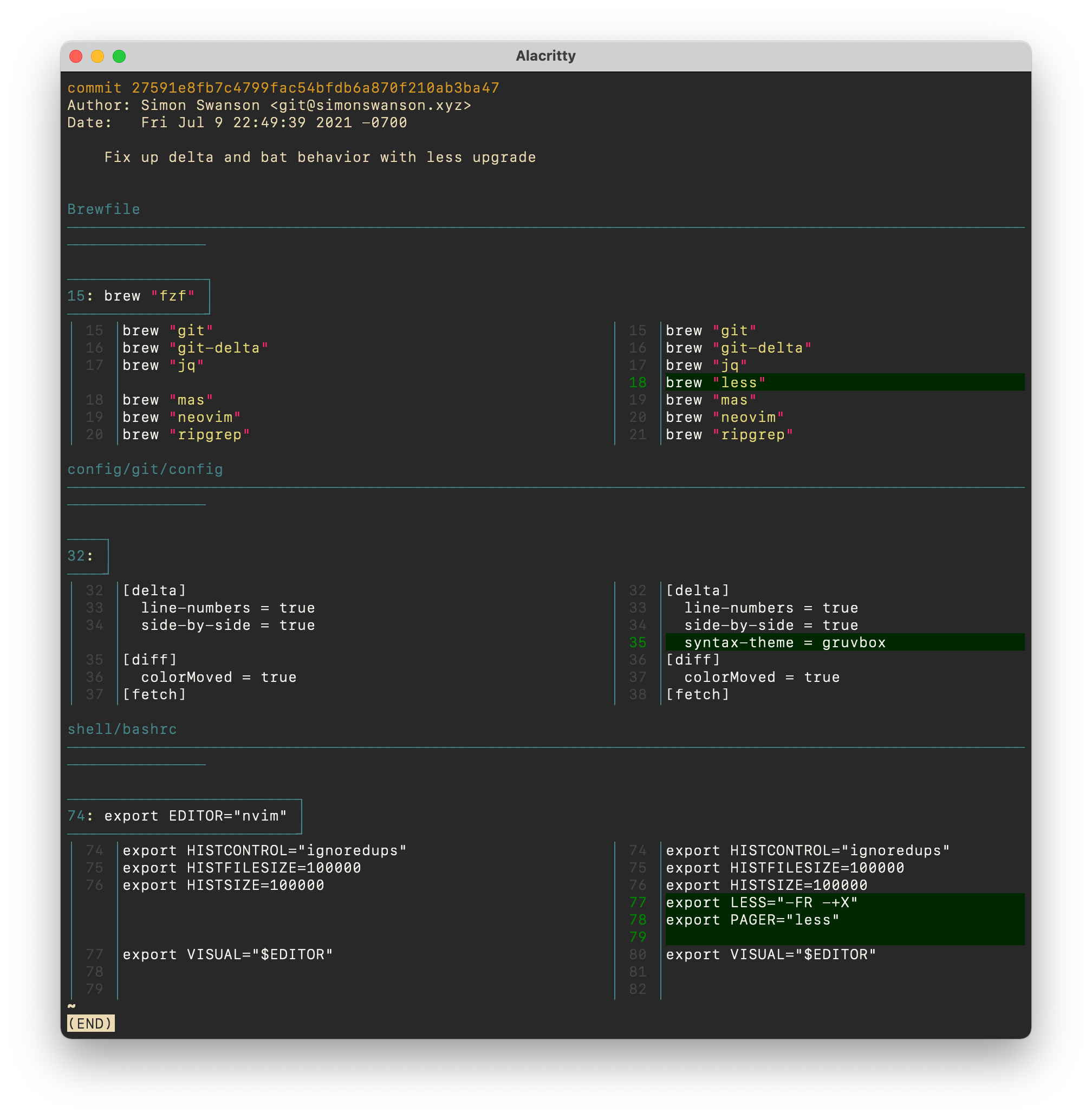
There's nothing inherently wrong with working this way: in fact, this is how development happens! We make changes, try them out, and then make more changes on top of that. We then realize that something else went wrong, and write up a change for that. The natural development workflow is that of the fixup commit, and I think that's why it's so prevalent.
But just as we impose restrictions on our code by insisting on functional or object oriented patterns, or demand that we structure our service meshes in specific ways, you may find that imposing restrictions on your commit habits is useful. When every commit must be a fully-formed unit of work, you may think differently about your code change.
A feature that requires many individual units of work can be slowly added to the core codebase (and hidden behind features flags or other tools), where it can undergo constant testing and integration with code from other developers, instead of living on a long-lived feature branch with manual integration with the base branch. And when we need to examine the history of a piece of code, working with fully-formed commits means that every entry in the git blame will point to both the source and the reasoning behind the change. We can see all the affected landscape at a glance and see how that change fit into the rest of the system.
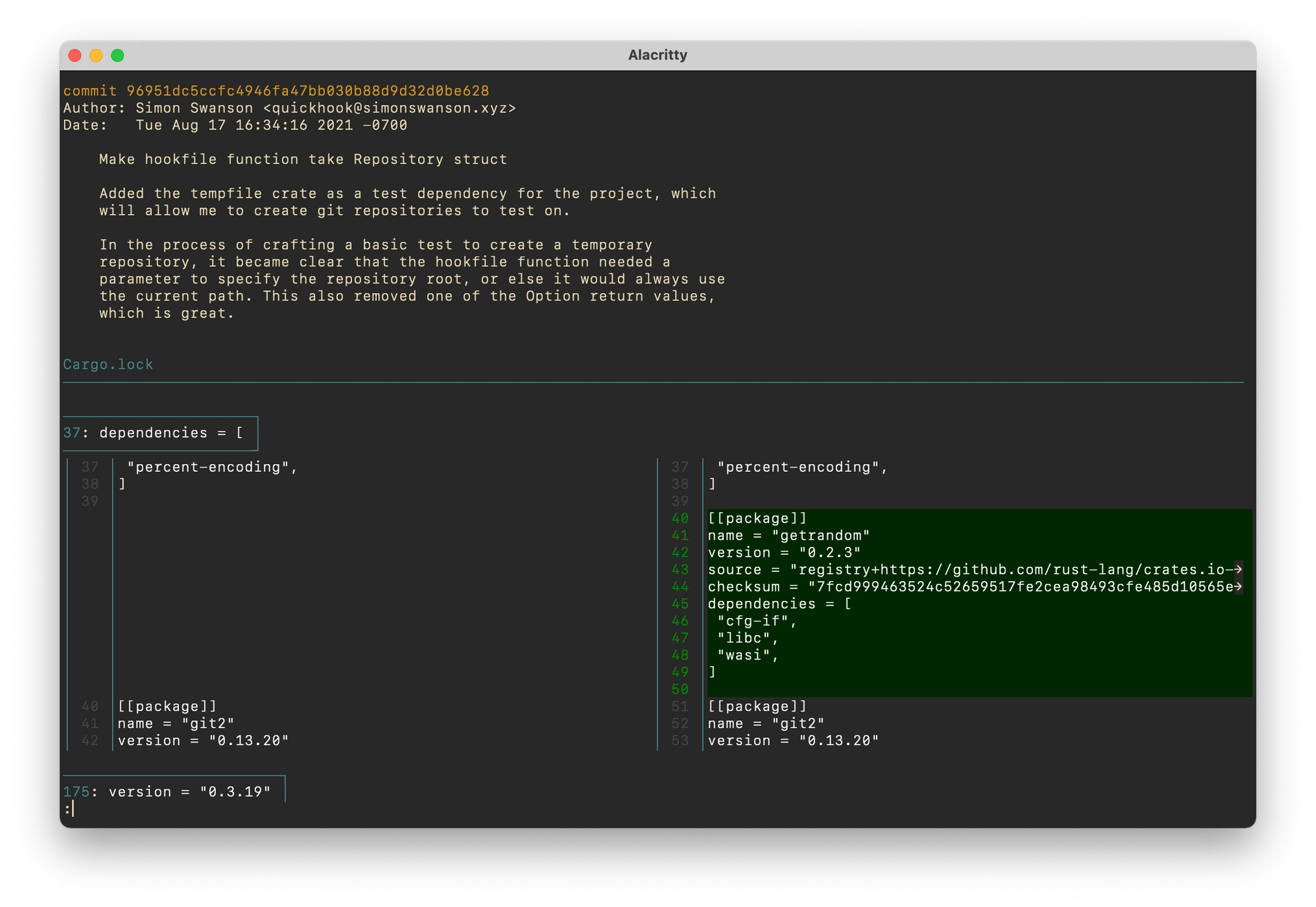
I've encountered concurrent projects that have, as a result of incremental, single commit merges, produced beautiful systems with low developer friction, despite these projects constantly producing merge conflicts with each other. Every time the developers push new code, it's grouped into well-defined, fully-formed ideas. There are no "Merge origin/main into main" commits with mysterious diffs; every single commit works on top of the base branch and has a meaningful description, and there's no panic merging and conflict resolution when the change needs to get merged.
I've also seen concurrent projects work with an "always adding commits" approach, but they're inevitably incredibly high friction for the reviewers and the developers involved. When developers push arbitrary "fix" commits and the reviewer sees a new thing in their inbox, it's never quite clear if the change is quite ready for review. It's never quite clear how the review should be done. Some reviews should be "all files that are changed" while some are better understood by going commit by commit and seeing the evolution of an idea. Sometimes the incremental change looks unrelated to the rest of the changed code, and only when viewing it in context does it begin to make sense.
Is this the same as "one commit per merge"?
No.
While Gerrit enforces this constraint, and I thank Gerrit for forcing good development habits onto my workflow, this is actually unrelated to the number of commits in a merge.
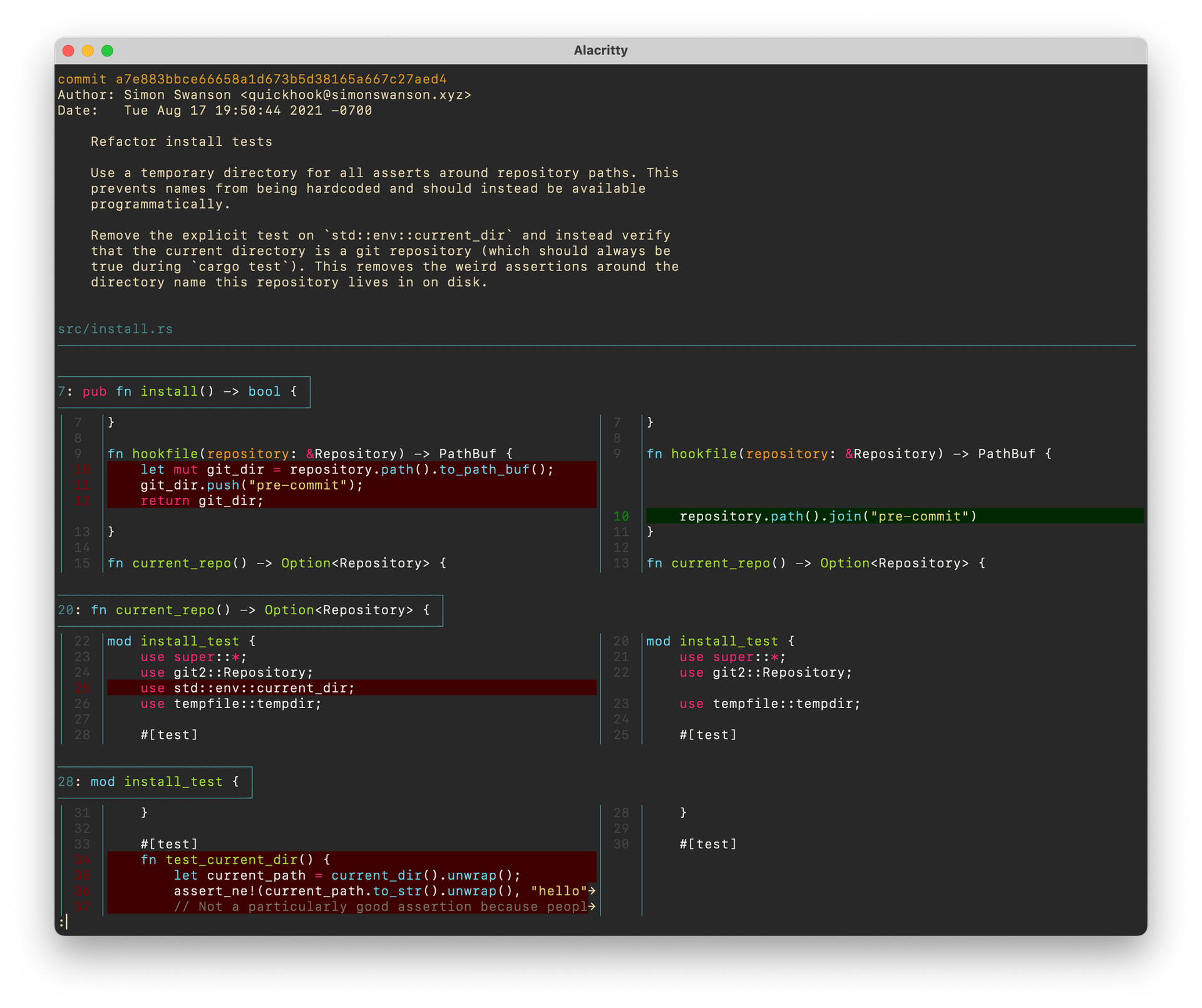
I recently merged a pull request with 18 commits. While certainly an anti-pattern of sorts, every single commit in the chain could have been merged independently (in that same order) and kept the tests and builds running smoothly. The problem was that it was nonsensical as a single commit: only around commit 14 or 15 did it become clear what advantages there were to the rewrite I had undertaken. This, again, is how development works: to enact structural changes we often need to recompose other parts of the system in a way that looks, at least temporarily, like a worse option.
But now when anyone goes into my code and tries to find out why something was built in a certain way, or how it was constructed, they can trace through my commits. And not just through code, but through my commit messages (likely a follow up post) and my pull request descriptions (also likely a follow up). When they go looking for answers, the answers will be there and not hidden behind layers of "fix me" commits.